
Exploratory Analysis on Loan Defaulting Dataset
Introduction
A default is the failure to make required interest or principal repayment of a debt. Loan defaulting can be due to a number of reasons including but not limited to income loss, poor financial management, family issues and natural disasters. Many companies have recorded data on every of their clients from all ages and all walks of life. This project explores those collected data using Python for both analysis and visualization. The project highlights the likelihood that a person will default on their loan based on their past history and personal data provided.
Data Cleaning
The dataset used for this analysis was gotten from Kaggle, here is a link to access it https://www.google.com/url?q=https://www.kaggle.com/datasets/gauravduttakiit/loan-defaulter&sa=D&source=editors&ust=1728244097228068&usg=AOvVaw0Y9BAQTIKcR5Gn_9FRou6w.
I made some adjustments to the data, they are listed below:
I dropped some columns after realizing they not only had a high percentage of null values they were also irrelevant to my analysis.
Some Boolean values were replaced with 0’s and 1’s for easier analysis.
Data Exploration
A total of 307511 client info was used for this analysis. 90% of the total opted for a cash loan type, while the remaining 10% chose a credit loan type.
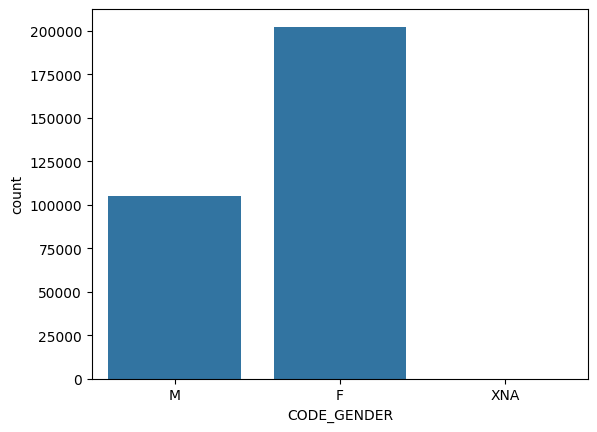
Fig 1; Bar chart showing the contract types available
Also, 66% of the clients were female while 34% were male. This distribution reveals that the women who requested for loans were two times as many as their male counterparts.
Fig 2; Bar chart showing the gender of clients
It was also revealed that a large number of the client didn’t lie and work in the same city suggesting that they either worked remotely or didn’t actually have a job.
Out of 307511 clients, 30% had higher education, 65% stopped at secondary level, 3.6% did not complete their higher education and the rest fall below that.
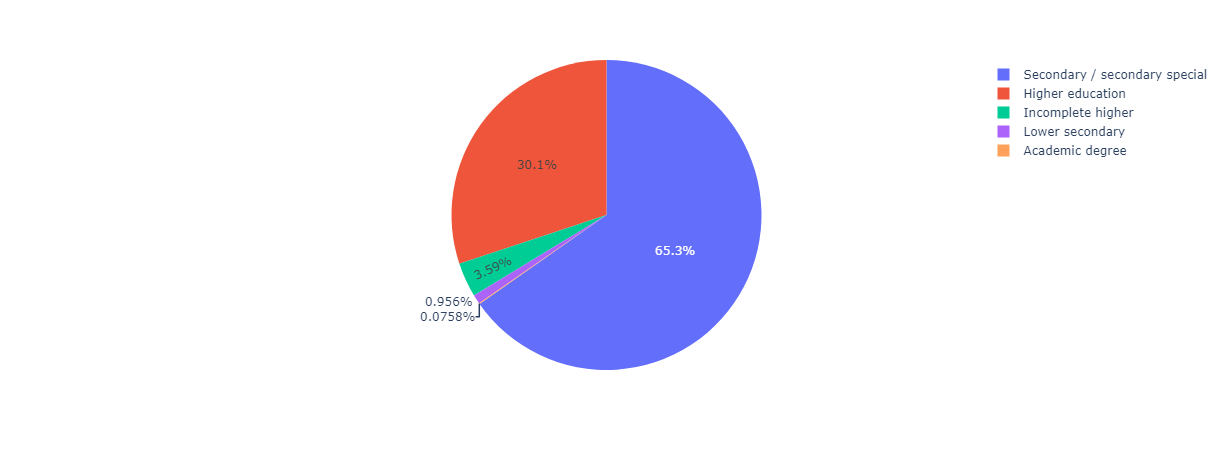
Fig 3; Pie chart showing Education types of clients
My analysis focused on exploring this datasets and identifying trends. A more in-depth analysis and simulation of this dataset will be required in order to make predictions/recommendations.
Conclusion
The goal of this analysis was to understand and highlight the likelihood of a client to default on their loans based on their past history. The analysis revealed a few things already stated above. These findings suggested that not all data submitted are 100% accurate. It was also revealed that things like the client’s gender, age and number of children were not a factor to whether or not they would default on their loans. While this analysis revealed certain things, future research could benefit from a broader dataset to help in a deeper analysis.


